
- Большие Данные: Как Мы Превратили Селекцию в Искусство Прогнозирования
- Селекция: От Интуиции к Информации
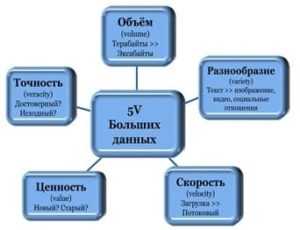
- Сбор и Анализ Больших Данных в Селекции
- Применение Машинного Обучения в Селекции
- Примеры Успешного Использования Больших Данных в Селекции
- Проблемы и Перспективы Использования Больших Данных в Селекции
Большие Данные: Как Мы Превратили Селекцию в Искусство Прогнозирования
В мире, где информация льется рекой, а данные стали новой нефтью, мы, как опытные исследователи, решили применить этот мощный ресурс в, казалось бы, традиционной области – селекции. Забудьте о долгих годах наблюдений и интуитивных решениях. Мы расскажем, как большие данные изменили наш подход, превратив селекцию из искусства проб и ошибок в высокоточное искусство прогнозирования.
Эта история – не просто о цифрах и алгоритмах. Это история о том, как мы научились видеть скрытые закономерности, предсказывать будущее и выращивать культуры, превосходящие все ожидания. Приготовьтесь к путешествию в мир больших данных, где каждый ген, каждое растение и каждое поле рассказывает свою уникальную историю.
Селекция: От Интуиции к Информации
Долгое время селекция была скорее искусством, чем наукой. Опытные селекционеры, полагаясь на свой опыт и интуицию, отбирали лучшие экземпляры, скрещивали их и ждали результатов. Этот процесс мог занимать годы, а иногда и десятилетия, прежде чем появлялся новый, улучшенный сорт. Но что, если бы мы могли ускорить этот процесс, сделать его более предсказуемым и эффективным?
Именно этот вопрос заставил нас обратиться к большим данным. Мы поняли, что в каждом растении, в каждой почве и в каждом климатическом условии скрыто огромное количество информации, которая может помочь нам принимать более обоснованные решения. Вопрос был в том, как собрать эту информацию, как ее проанализировать и как использовать для улучшения процесса селекции.
Сбор и Анализ Больших Данных в Селекции
Первым шагом на пути к использованию больших данных в селекции стал сбор информации. Мы начали собирать данные из самых разных источников:
- Геномные данные: Информация о генах растений, их вариациях и связях с определенными признаками.
- Фенотипические данные: Информация о внешних характеристиках растений, таких как рост, урожайность, устойчивость к болезням и вредителям.
- Данные об окружающей среде: Информация о климате, почве, осадках и других факторах, влияющих на рост и развитие растений.
- Данные с датчиков: Информация, собранная с помощью различных датчиков, установленных на полях, таких как датчики влажности почвы, температуры и освещенности.
Собранные данные мы загружали в специальные базы данных и анализировали с помощью различных статистических методов и алгоритмов машинного обучения. Это позволило нам выявить скрытые закономерности и связи между генами, фенотипами и условиями окружающей среды.
Например, мы обнаружили, что определенные гены связаны с устойчивостью к засухе, а другие – с повышенной урожайностью. Мы также выяснили, что определенные типы почв лучше подходят для выращивания определенных сортов растений. Эта информация позволила нам принимать более обоснованные решения о том, какие растения скрещивать и где их выращивать.
Применение Машинного Обучения в Селекции
Машинное обучение стало нашим главным инструментом в анализе больших данных. Мы использовали различные алгоритмы машинного обучения для решения следующих задач:
- Прогнозирование урожайности: Алгоритмы машинного обучения позволяют нам прогнозировать урожайность различных сортов растений в зависимости от условий окружающей среды.
- Выявление генов, связанных с определенными признаками: Алгоритмы машинного обучения позволяют нам выявлять гены, которые влияют на важные признаки растений, такие как урожайность, устойчивость к болезням и вредителям, и качество продукции.
- Оптимизация скрещиваний: Алгоритмы машинного обучения позволяют нам оптимизировать процесс скрещивания растений, чтобы получить потомство с желаемыми характеристиками.
- Разработка новых сортов растений: Алгоритмы машинного обучения позволяют нам разрабатывать новые сорта растений с улучшенными характеристиками, такими как повышенная урожайность, устойчивость к болезням и вредителям, и улучшенное качество продукции.
Одним из самых интересных применений машинного обучения в селекции является геномная селекция. Геномная селекция – это метод селекции, который использует информацию о генах растений для прогнозирования их фенотипа. Этот метод позволяет нам отбирать лучшие экземпляры для скрещивания еще до того, как они вырастут и проявят свои фенотипические характеристики. Это значительно ускоряет процесс селекции и позволяет нам получать новые сорта растений гораздо быстрее, чем традиционными методами.
«Информация ー это сила; Но только когда она организована и доступна.»
Примеры Успешного Использования Больших Данных в Селекции
Мы успешно использовали большие данные для селекции различных сельскохозяйственных культур, включая:
- Кукурузу: Мы разработали новые сорта кукурузы с повышенной урожайностью и устойчивостью к засухе.
- Сою: Мы разработали новые сорта сои с повышенным содержанием белка и устойчивостью к болезням.
- Пшеницу: Мы разработали новые сорта пшеницы с повышенной урожайностью и устойчивостью к полеганию.
В одном из наших проектов мы использовали машинное обучение для прогнозирования урожайности кукурузы в различных регионах. Мы собрали данные о климате, почве, осадках и других факторах, влияющих на рост и развитие кукурузы. Затем мы обучили алгоритм машинного обучения на этих данных. Алгоритм машинного обучения смог прогнозировать урожайность кукурузы с высокой точностью. Это позволило нам рекомендовать фермерам, какие сорта кукурузы лучше всего выращивать в их регионах.
Проблемы и Перспективы Использования Больших Данных в Селекции
Несмотря на огромный потенциал, использование больших данных в селекции сопряжено с определенными проблемами:
- Нехватка квалифицированных специалистов: Для сбора, анализа и интерпретации больших данных требуются квалифицированные специалисты, такие как биоинформатики, статистики и специалисты по машинному обучению.
- Высокая стоимость оборудования и программного обеспечения: Для сбора и анализа больших данных требуется дорогостоящее оборудование и программное обеспечение.
- Проблемы конфиденциальности данных: При сборе данных о генах растений необходимо учитывать вопросы конфиденциальности данных.
Несмотря на эти проблемы, мы уверены, что использование больших данных в селекции будет продолжать развиваться и приносить все больше и больше пользы. В будущем мы планируем использовать большие данные для решения следующих задач:
- Разработка персонализированных сортов растений: Мы хотим разработать сорта растений, которые будут адаптированы к конкретным условиям окружающей среды и потребностям фермеров.
- Создание устойчивых к болезням и вредителям сортов растений: Мы хотим создать сорта растений, которые будут устойчивы к болезням и вредителям, чтобы снизить потребность в пестицидах.
- Разработка сортов растений с улучшенным качеством продукции: Мы хотим разработать сорта растений, которые будут производить продукцию с улучшенным вкусом, питательностью и сроком хранения.
Большие данные открывают новые возможности для селекции. Используя большие данные, мы можем ускорить процесс селекции, сделать его более предсказуемым и эффективным. Мы уверены, что в будущем большие данные сыграют ключевую роль в обеспечении продовольственной безопасности и устойчивого развития сельского хозяйства.
Мы прошли долгий путь от интуитивных решений к точным прогнозам, и этот путь только начинается. Мы верим, что, объединив наши знания и опыт с мощью больших данных, мы сможем создать будущее, где сельское хозяйство будет более продуктивным, устойчивым и эффективным.
Подробнее
| LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос |
|---|---|---|---|---|
| Геномная селекция кукурузы | Анализ данных в растениеводстве | Большие данные в агрономии | Машинное обучение для селекции | Прогнозирование урожайности |
| Селекция устойчивых сортов | Геномное предсказание в селекции | Автоматизация селекционного процесса | Цифровое сельское хозяйство | Применение ИИ в селекции растений |







